Getting Unstuck
Context
I wanted to rewrite a personal application, and I was stuck.
Then I came across a blog post that inspired me (https://steipete.me/posts/2025/shipping-at-inference-speed).
I emulated the setup, and I finished rewriting this small project.
From it, I decided to tackle a slightly bigger one.
I was stuck due to execution speed:
I was using Cursor and Docker deployment on a personal server.
Code quality was decent, but the delivery was too slow.
I then turned to:
- Development on a private server, using Git to track progress.
- Multiple agents (Claude Code / Codex) to handle operations such as coding, commits, and data operations (trigger endpoints and fix data bugs).
- Empty CLAUDE.md
- Evolve only when needed (e.g. update infra when serving is slow)
I started with:
- Python backend with one hello-world endpoint.
- React frontend.
- FileSystem as permanent storage.
- DuckDB as serving layer.
Within two weeks, the application evolved into:
- 20+ endpoints
- a frontend that handles both visualization and admin operations
- multiple stable workers
- S3 as permanent storage
- Postgres as serving layer (with migrations)
- bare-metal deployment on two machines (one for dev, one for stable)
- 10k lines of code
Additional information:
- Stable application: https://train-tracker.pguardati.me
- It is login-protected to avoid hammering a small machine and to prevent a license dispute with the data provider
Current spending is 35 Euros/month:
- 20E/month for agents (2 weeks of Claude Pro and ChatGPT Pro)
- 10E/month for two 2GB RAM Hetzner VPS instances
- 5E/month for 1TB Hetzner Object Storage
Infra Evolution
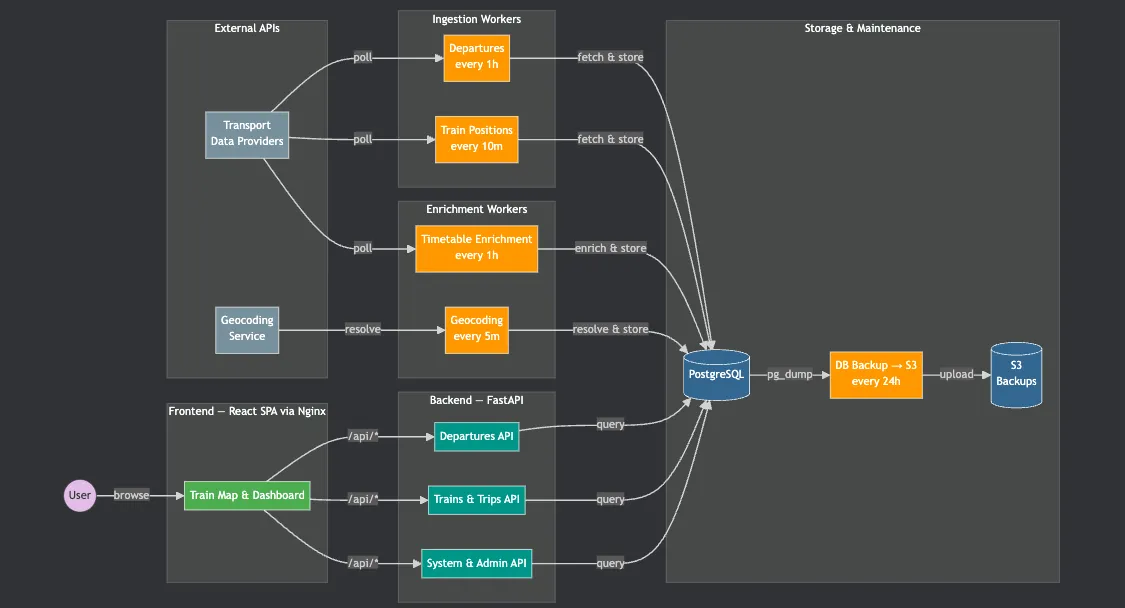
As I mentioned before, the project started with a simple infrastructure:
Single FastAPI endpoint, DuckDB as serving layer, File system as storage layer
Additionally, I had no idea what data the provider would supply, or what I was exactly going to build.
”I just want to do a train timelapse with real data while keeping control of the application”
The key initial design choice was to use an API with a ‘real’ frontend.
I used Streamlit in a previous project, but the agent ended up coupling the logic to the UI.
Using an API, I noticed that the agents naturally separated the concerns.
Up to a certain point, the approach was:
- Ask the agent to implement a feature.
- Ask it to commit, push, deploy, and verify it was working.
It worked until feature size required substantial refactoring.
Development was breaking too often - which stopped the data collection.
I really wanted to spend only 5E/month, but data collection continuity forced me to create an infrastructure clone (on
the same machine) and to introduce a worker to back up the databases.
To overcome DuckDB single-writer limitations and to control the data model remotely with proper transactions, I switched
to
Postgres.
Even with the application clone working for a while,
the agent deployed WIP features to the stable infrastructure by mistake and broke the collectors.
Only then I added one more €5 machine and deployed the application there.
Prompting the agent to set up the server, download the repo, and trigger the endpoint to restore the database from the
backup worked smoothly.
Because I was using two machines, I couldn’t ask the agent to update the stable application anymore.
Setting a CI/CD action to deploy on merge solved the issue and turned the workflow from reviewing commits to generating
and reviewing PRs.
It also improved commit messages and code quality.
(“squash and split commits to separate iterations, make the CI green”) pushed the agent to use standard commit messages
and pass the linters.
Few considerations:
- There are routines that could be stored as ‘skills’, but prompting manually still worked decently.
- I was already aware of good practices (linters, commit standards, PRs, CI/CD, migrations) but I wanted to postpone them on purpose.
- I noticed an agent starts with simple implementations and turn into OOP designs on their own as the app scales.
Final comment:
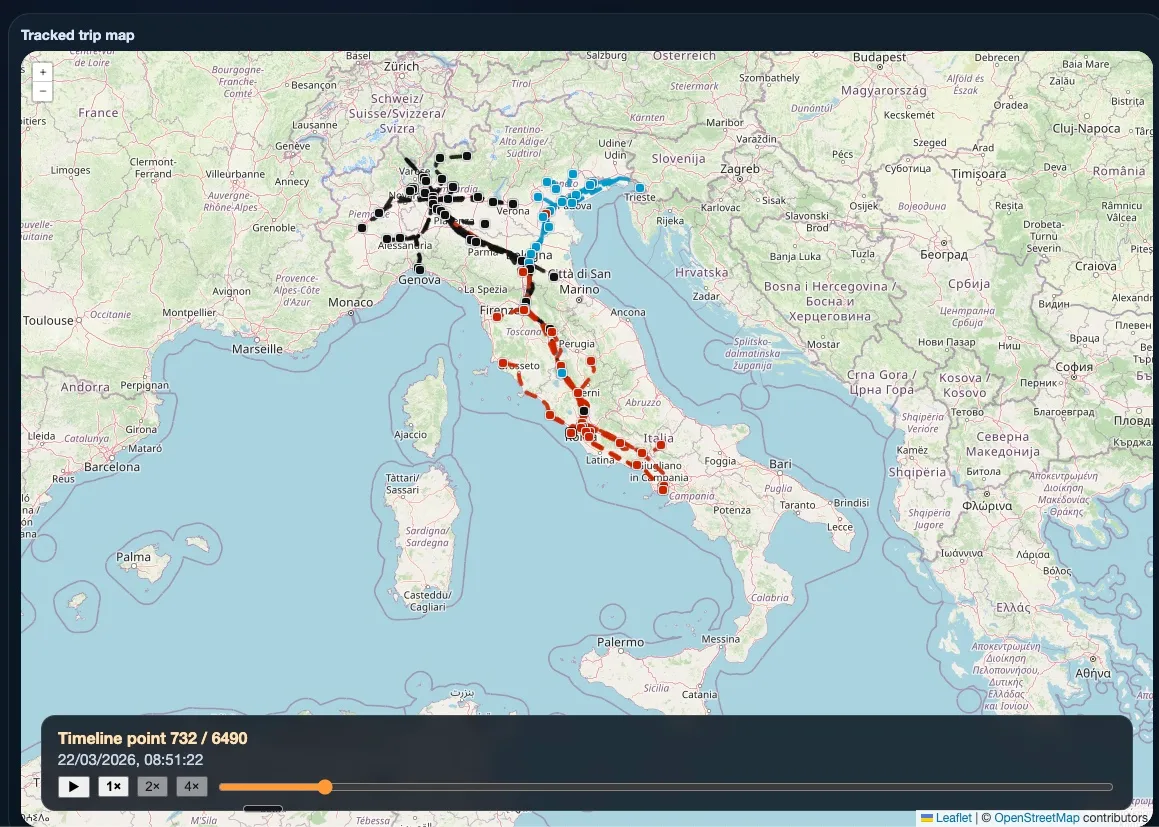
The first project I built with this approach was the third version of a simple thermostat downloader and visualizer. The first version was local-only. The second one was deployed, but it had manual API authentication and coupled the backend and frontend. The third one was deployed and is fully automated. ~5k LOC.
This second project is a potentially scalable analytics application. (more trains, more stations, more providers, more servers to scale distribution, add data quality and strategy, etc.) ~10k LOC so far, and it has been fun to build. I am considering shutting down the data collector for economic reasons, but I am curious to continue pushing the limits of what could be built with these tools.